—A Survey of Common Parallel Applications, from a Programmer’s Perspective
Group members:
Briefly, what is it about?
We are building a mesh multiple machines (Raspberry Pi) where parallelizable applications could have their work distributed over to various computing resources, so good speedup can be observed. We hand-built the cluster architecture, wrote lower level code to let different machines communicate, and wrote several applications (SHA256, large array sorting, and matrix multiplication and etc.) to test its performance. We hope to demonstrate through the cluster some of the benefits of the supercomputers that cluster relatively cheap cores, as well as the difficulties in such system.
Code base: https://bitbucket.org/CCing/15418-final-project
How did we come up with this?
In theory, a lot of programs are parallelizable. For applications that are high in work but low in span, a mesh of weaker processors can achieve similar performance to that of a single beefy processor. From the angle of processor costs, weaker processors are more affordable. As for energy consumption, multiple processors running at lower frequency is using less power than a single beefy core working at full throttle.
In practice, we realize that in most of the in-class assignments and projects, we are provided with rich starter code so that we could focus on the most significant algorithms. But in this project we also have to build up the whole architecture as well as writing lower level code that closely relates to the hardware. So we believe that this project would lead us into insights of a parallel, distributed computer architecture, which we couldn’t gain from only lectures and assignments.
What gadgets / software are we talking about here?
For hardware, we are using 4 Raspberry Pi’s and 1 ethernet switch. The Raspberry Pi has a quad core ARM processor, with 1GB of RAM. The ethernet switch supports up to 100 Mbps of point-to-point transmission rate.

Software: Each of the Pi’s is running on Raspbian OS, with MPI installed. The parallel programs we write are in C++. We also rely on interactive scripting language to achieve certain automation processes, such as batch compile and execute.
What architecture our system adopts?
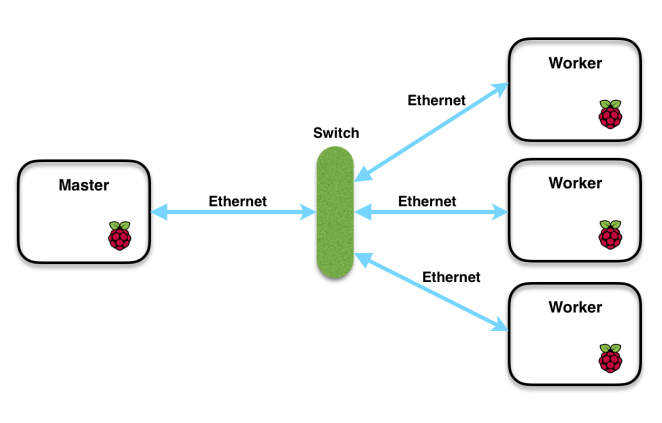 We use the master-slave model. One node is a master node that is responsible for allocating work and receiving results while the other 3 are worker nodes that receive work and do computations. Thanks to the convenience brought by MPI, we can write our code in one file and deploy the same code on all machines and MPI will run different parts of the code based on the rank of the process (an assigned id for each node).
We use the master-slave model. One node is a master node that is responsible for allocating work and receiving results while the other 3 are worker nodes that receive work and do computations. Thanks to the convenience brought by MPI, we can write our code in one file and deploy the same code on all machines and MPI will run different parts of the code based on the rank of the process (an assigned id for each node).
In applications that we have built, master is responsible for task division, task distribution and result merging if necessary. And workers receive the assigned work, computes what is needed and send results back. All the communications are MPI based on ethernet (~100Mbps), which is fast enough for normal message passing, but may still become bottleneck for data intensive applications.
What got in our way?
Before we decided that an ethernet switch is our interconnect solution, we had a hard time deciding how we should build the interconnect, because we were not sure of their performances.
Considerable amount of time was spent on enabling each of the machines to communicate, through the terminal, Python and C++.
We desired that this cluster will appear to the user like a single computer, where all the implementation details of the mesh are hidden at runtime. To let all the Pi’s coordinate, we had to provide certain automation process, so that all the worker Pi’s could be given a workerId, receive source code, compile, execute with designated arguments at the same time with the master Pi, return computed values back to master Pi, all within one line of command in the terminal of the master Pi.
A lot of effort is put into knowing the limits of each components of the architecture, i.e., the computation power of each node, the specifics of their memory hierarchy, bandwidth of data transmission over different nodes, so that we could let the whole system to have balanced load when running applications.
Are there noticeable outcomes of this project?
We managed to let the cluster appear to users as one single computer, by using Python as interactive scripting language, as well as adding SSH authentications to avoid repeated password prompting for data transmission. So now we could SSH into master Pi, type a line for batch execution, then all worker Pi’s will automatically compile, run, take the work and return results to master, without the user knowing.
At the same time we exposed certain details of load balancing to the application: a program would have to partition the work into smaller sizes, so that a piece of “sub-work” could be dispatched to a worker Pi that is not so busy.
We wrote and ran several applications, getting statistics over sequential and parallel versions.
Pseudo SHA256 “Salt” Cracking, outrunning a for loop by making everything parallel
The SHA256 pseudo “salt” cracking application involves massively computing hash values. We compute those values on a give range of keys in a brutal-force manner, and parallelize the work on the cluster. We spawn some threads in the master Pi, in which we pass along the input (message) and the SHA-256 values (checksum values) to worker Pi’s using MPI. Upon receiving the messages, the worker Pi’s try to find the “salt” (key of the complicated hash function) in parallel, and send back the cracked key to the master Pi. Since the task is embarrassingly parallel, the results are phenomenal.
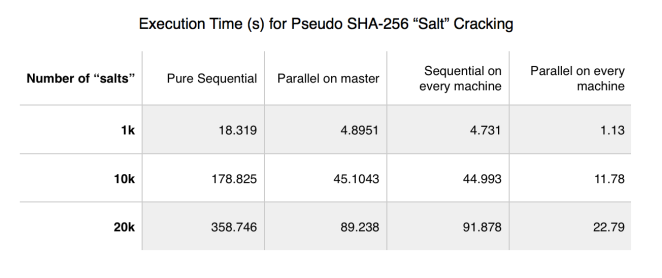
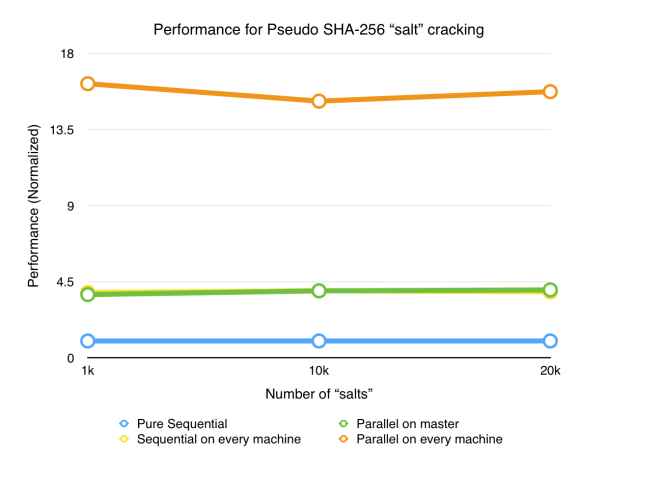
As seen from the graph, very good speedup is obtained. On 4 cores (either 1 node x 4 cores or 4 nodes x 1 core), the speedup is about 3x as there are 3 worker nodes computing SHA256 on different sub-ranges. And on 4 nodes x 4 cores, the speedup gets to about 11x. Speedup is phenomenal; the communication overhead only slightly prevented the speedup from being 4x and 16x.
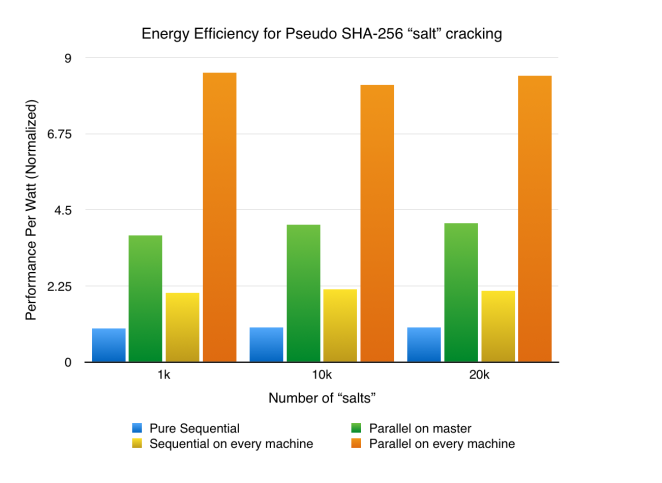 Notice that when the application is run in parallel, but sequentially on each machine, the energy efficiency is still higher than that of run on single machine sequentially. However it is not as efficient as the program being run on a single machine, but in parallel. This is due to the lower utilization of computing resource of each machine. When the program utilizes fully the computing resource the cluster has to offer, the energy efficiency is the highest.
Notice that when the application is run in parallel, but sequentially on each machine, the energy efficiency is still higher than that of run on single machine sequentially. However it is not as efficient as the program being run on a single machine, but in parallel. This is due to the lower utilization of computing resource of each machine. When the program utilizes fully the computing resource the cluster has to offer, the energy efficiency is the highest.
Evaluation: The work is internally highly parallelizable and we did manage to implement a version that runs much faster with much higher energy efficiency. Pi is considered a good platform in this case because parallelism in various layers are successfully deployed over the cluster.
Sorting (C++ builtin), beating “array.sort()” by ~900 lines of code
We attempted to parallelize sort of large integer arrays. The basic approach is to first divide the large array into “buckets”, each of which contains elements in some range of values, and then distribute the buckets to worker node to sort. Workers send back the sorted array and the master node store the results accordingly. This application is memory consuming and involves intensive data transfer, posing a big challenge for parallelization to be effective.
We ran the c++ builtin sort with large input sizes. Over different versions, we saw different degrees of speedup, but not all of them are ideal.

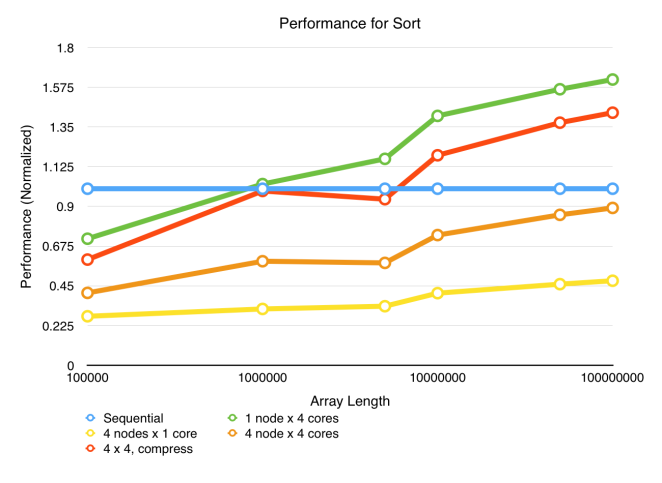
Sequential (blue): the baseline we wrote that simply sorts the entire array. (The sequential code is also compiled by mpic++, which exhibits a surprisingly 4x~8x speedup than g++ compiler, presenting us with a very challenging task to compete with this baseline.)
4 nodes x 1 core (yellow): First try. Deploy parallel code with MPI on four machines without utilizing multi-core parallelism on each machine. The result is bad, but as expected, because without multicore parallelism latencies in sending array chunks around cannot be hidden.
1 node x 4 cores (green): Deploy the code only on 1 machine but utilizes all 4 cores. The result is very good, as remains as the best as it eliminates all bandwidth limitations that are involved in multi-node communications.
4 node x 4 cores (orange): The hardest try made ever. We optimized the code to squeeze out as much parallelism as possible, including having a balanced load on each worker machine, having each worker both receiving work and computing work on different cores to hide bandwidth latency, and parallelizing the bucket dividing job on master node. But computation-bandwidth ratio is too low. Great effort does not always lead to great result.
4×4, compressed (red): Determined to increase computation-bandwidth ratio, we compress the array chunks to be sent/received, by using a short to represent each array integer, thus doubling the effective bandwidth. The result is satisfactory, but still does not beat the single node parallel version.

The energy analysis shows that the 1 node x 4 cores deployment is the most energy efficient. This makes sense because this version also produces the best performance, plus that it only consumes dynamic power on one node while other nodes in the cluster only consume static power or can compute other tasks.
This application clearly demonstrates that parallelization on a cluster is not always desirable and can even be wasteful despite of large efforts put into the work. A cluster connected by ethernet will very likely be bandwidth bound when executing data intensive computations, subsequently degrading the performance of parallelism and thus energy efficiency.
Evaluation: In this data-intensive application, performance is majorly impaired by low data transmission rate. The fact that running a data-intensive program by fully using one node is the fastest demonstrates a common property of computing clusters: communication over different machines is almost always slower and less efficient in energy than over different cores within one single machine.
Matrix Multiplication, defeating a nested for loop by parallelism with high compute-to-data ratio
Learned from the difficulties from parallelizing sort above, we were looking for parallelizable applications that exhibit larger computation intensity in order to hide the large amount of data transfer latency among nodes. And matrix multiplication, especially float multiplication, came into our mind. After some simple baseline experiments, we found that with the same amount of data, float matrix multiplication requires the execution time a few time higher than sorting that size of data, thus having the potential to hide the ethernet bandwidth latency.
Similar setup of the system is used, and the strategy for parallelization is: to compute matrix multiplication A x B = C, the master node send B to all workers, and chunks (a few rows) of A to each worker. The results back are chunks of C. The parallel code is deployed on different number of nodes and number of cores per node to compare the results. The multiplication code applies the blocking method that divide matrices into small blocks to utilize cache locality (which brought a large degree of speedup to the naive multiplication version, but this comparison is not presented here). Below are the results (work size is the dimensions of matrices: A[N][N] X B[N][N]).
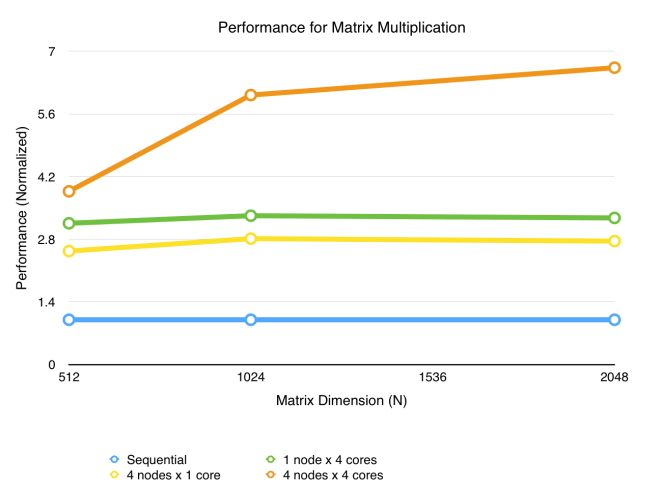
Sequential (blue): The basic version that runs on single node single core with blocking method. This serves as the baseline for any further speedup.
1 node x 4 cores (green) vs. 4 nodes x 1 core (yellow): Both exhibit about 3x speedup. The multi-node version, as expected, is slower than the one node multi-core version, partly because of the communication costs and overheads in setting up work distribution.
4 nodes x 4 cores (orange): As work size increases, speedup also rises, initially fast because communication overhead becomes less significant in proportion to the work, and then slowly as the speedup is being compute-bound, as we hypothesize.
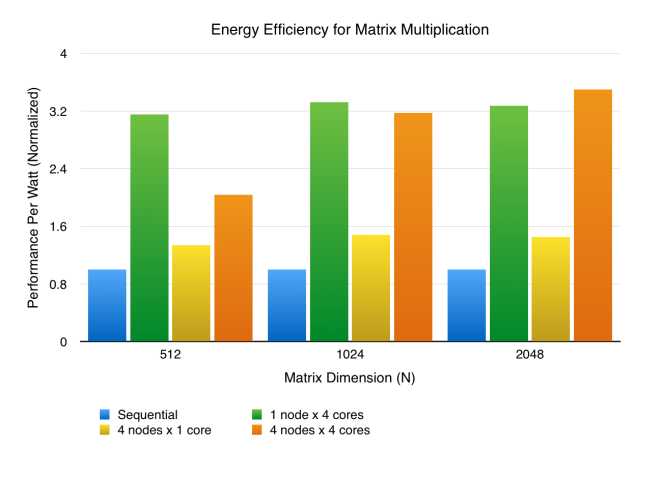
From the energy analysis, the 1 node x 4 cores, similar to sort, still has an advantage in power efficiency as it has relatively good performance while only uses 1 node. However, another trend is that 4 nodes x 4 cores is catching up, and even becomes better when work size is large. When the work size increases, the speedup also rises as mentioned above, but the power usage remains constant, so performance per watt is able to rise as well.
Evaluation: Speedup with parallelism adopted is also phenomenal for this application. Since this application intensive in both data and computation, whether the cluster is compute-bounded or memory-bounded is not so deterministic; different matrix dimensions yield different answers. In this application we consider Pi not the optimal platform, because the processor (homogeneous, quad-core ARM Cortex-A7) has weaker computing abilities than newer versions of ARM processors, especially on floating point computations. If Pi’s are to be replaced with processors that are highly optimized in floating point execution, the application might spend a larger fraction of time on transmitting data, which would lead to different statistics.
It is interesting to see different results as compared to the sort application and the two applications both have excessive amount of data transfer through ethernet. The point that makes the difference is the ratio between the time spent on working the data chunk against the time cost of sending the data as well as the corresponding result. Sort has a low ratio, so the parallel application is bandwidth bound. Matrix multiplication has higher ratio, making it possible to hide the bandwidth latency, thus the parallel application is compute bound.
So, how did we do?
In short, we are satisfied with our project as well as the Pi cluster we have built. The architecture is representative of a general purpose HPC cluster that uses many nodes and connects them through ethernet. Such system brings performance, and avoids users to interact with all nodes but only deploy the work on master node and the master will automate the interaction with workers. From this aspect, we are glad that we can achieve such behavior as well.
Certainly we are not expecting the system to compete with normal computers as it does not match the computing powers of modern computers and also has limitations on communication. However, it is still able to do a good job on parallizable computation intensive workloads. More importantly, throughout developing applications for the system, we identified a common pattern of work flow in those application. This allows the potential to build a framework for the system to deal with most common parallel applications (More specifically, the work partition, work distribution, work computations and result collection workflow). With such framework available, we can build parallel programs more easily for both testing and real-life use purposes.
What did we learn out of this project?
Briefly explained, the build-up of this project is adventurous experience where we practiced a majority of parallel thoughts from the class of 15-418.
More specifically, we now understand the multi-dimensions of the word “parallel”. To finish the work fast and efficiently is much more than just piling up a bunch of beefy cores and blissfully hope that program will use as much of the computing resources as possible (this is so 2004). Instead, we had to “think parallel” to achieve this:
We have to exploit the various layers of parallelism a computing cluster has to offer.
We have to gain specific hardware so the cluster’s performance wouldn’t be severely bounded by computing power or communication.
We have to rewrite software, not only for the applications to make better use of the cluster, but also let the cluster balance its loads.
We also realize that not all the efforts to parallelize an application pay off. In some applications that we try to parallelize, the program made use of more computing resources, but eventually finished the task with even longer time; this is one of the potential pitfalls of parallelization: not being consistent with Pareto Optimality.
Also while we were timing our applications, the cluster suddenly suffered from performance after being on for hours; we found out the cluster under-clocked because it was overheated. What we learned from this are:
When we are building up a cluster architecture, we have to consider the TDP of each components, and get prepared for the heat that it can generate.
We might see a cluster very performant for running a parallel program for minutes, but we probably should’t expect it to stick to peak performance for several hours or even days, because a machine could change its max throughput due to external factors, such as temperature.
Parallelization is hard, and performance efficiency is even harder! Sometimes we have to decide which side we want more, and it is extremely difficult to obtain both. We may want to make our program run slower to save some energy and other times to consume more power to make the application up to speed.
More specifically, what was our schedule?
Before April 4th: Brainstorming
April 4th – 11th:
– Obtain hardware and more research on work needed
– Determine the feasible applications to be run on the hardware
– Potentially get at least one node up and working.
April 11th – 18th:
– Assemble hardware and do the basic boot-up
– Achieve good communication between nodes
April 18th – 21st:
– Continuing optimizing for sort application
April 22nd – 25th:
– Start writing applications that are more compute-intensive
April 25th – 28th:
– Start trying visualize the results
April 28th – May 2nd:
– Continue optimizing the applications that we have
May 2nd – 5th:
– Blissfully take other final exams
– Optimize the applications
May 6th – 9th:
– Make final deliverable and writeup
– Prepare for demo
What else could we have done / will we work on in the future?
Knowing how to build up a computing cluster, we can easily replace Raspberry Pi’s with much more powerful computing resources, where the same applications we wrote will run with even more speedup. Or on the same cluster, we can build a framework to accommodate the current work flow as among applications we built we found a signifiant portion of overlap in workflow.
We can also look into GPIO pins of Raspberry Pi’s, which we can make use of to transmit data with a higher rate than ethernet.
We will further parallelize our applications, i.e. we will seek to make use of GPU’s on the Pi, as well as some ARM SIMD intrinsics.
We wish to also integrate certain logging schemes for computations, so that the computing cluster could be more fault tolerant.
